Vektordatenbanken in der KI – was sind Vektordatenbanken und warum sind sie so effektiv?
Was ist eine Vektordatenbank?
Vektordatenbanken unterscheiden sich von relationalen Standarddatenbanken durch ihren spezifischen Ansatz zur Speicherung von Informationen. Anstelle von Tabellen und Zeilen werden in Vektordatenbanken Daten in Form von Vektoren gespeichert. Vektoren sind mathematische Strukturen, die Daten als Mengen von Zahlen darstellen. Dank dieser Darstellungsmethode erreichen Vektordatenbanken eine hohe Effizienz bei der Datenspeicherung und -abfrage, insbesondere bei KI-bezogenen Aufgaben.
Vektor
Ein Vektor ist ein mathematisches Objekt, das Größe und Richtung hat. Er wird in verschiedenen Bereichen verwendet, z. B. wird in der linearen Algebra ein Vektor als geordnetes Tupel von Zahlen dargestellt, das die Position eines Punktes im n-dimensionalen Raum beschreiben kann. Vektoren sind die Bausteine für viele fortgeschrittene mathematische und wissenschaftliche Konzepte.
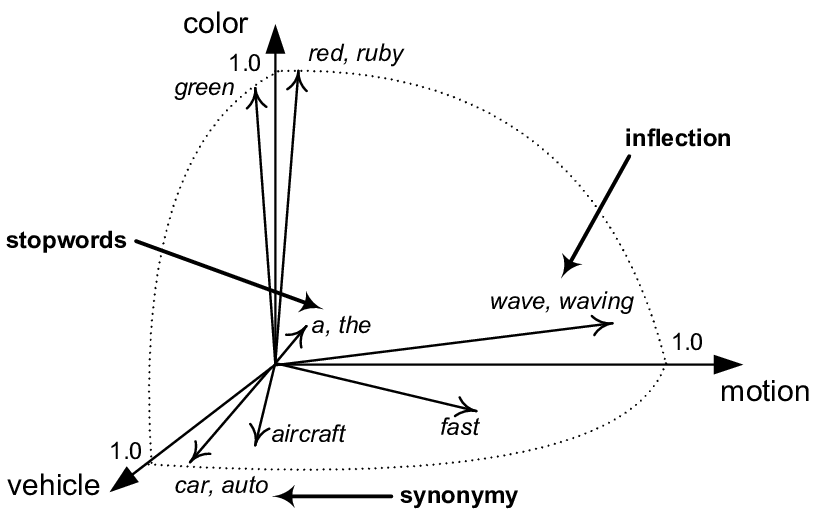
Die Hauptstärke von Vektordatenbanken liegt in ihrer Fähigkeit, mit Daten im so genannten Vektorraum umzugehen. In diesem Raum werden ähnliche Elemente durch Vektoren dargestellt, die sich in unmittelbarer Nähe befinden. Dadurch können Vektordatenbanken selbst bei unklaren oder komplexen Abfragen einfach und effizient ähnliche Elemente wie eine bestimmte Abfrage finden. Diese Funktion ist für KI-Anwendungen von entscheidender Bedeutung, da sie es maschinellen Lernmodellen und Systemen zur Verarbeitung natürlicher Sprache ermöglicht, effizient aus Daten zu lernen und Aufgaben wie Klassifizierung, Clustering und Datenanalyse durchzuführen.
Clustering
Clustering ist eine Methode des maschinellen Lernens und der Datenanalyse, die dazu dient, einen Datensatz in Gruppen oder "Cluster" zu unterteilen. Das Ziel ist es, die Daten innerhalb eines Clusters so ähnlich wie möglich zu machen, während die Daten in verschiedenen Clustern so unterschiedlich wie möglich sind. Das Clustering ermöglicht ein besseres Verständnis der Struktur und der Eigenschaften der Daten, ohne dass eine vorherige Kenntnis der Datenaufteilung erforderlich ist.
Durch Vektoren dargestellte Daten - was sind Einbettungsfunktionen?
Um die Vorteile von Vektordatenbanken nutzen zu können, müssen alle Daten in Vektoren umgewandelt werden. Einbettungsfunktionen spielen bei diesem Prozess eine Schlüsselrolle. Einbettungsfunktionen sind mathematische Werkzeuge, die Daten in den Vektorraum transformieren. Diese Funktionen analysieren die Daten und extrahieren wichtige Informationen aus den Daten, die sie dann in Vektordarstellungen kodieren. Einbettungsfunktionen können für eine Vielzahl von Datentypen verwendet werden, darunter Text, Bilder und Audio.
Einbettung von Funktionen
Die Funktionseinbettung ist eine Technik, die beim maschinellen Lernen und bei der Verarbeitung natürlicher Sprache eingesetzt wird und Objekte wie Wörter, Bilder oder Benutzerprofile in hochdimensionale Vektordarstellungen umwandelt. Diese Vektordarstellungen bewahren die semantischen Beziehungen zwischen den Objekten, was bedeutet, dass ähnliche Objekte ähnliche Vektoren haben werden. So hat beispielsweise die Vektordarstellung des Wortes "König" eine enge Beziehung zu den Vektoren der Wörter "Königin" und "Krone". Einbettungen erleichtern die Arbeit mit Daten in neuronalen Netzen und anderen Algorithmen des maschinellen Lernens, indem sie effiziente Vergleiche, Klassifizierungen und Ähnlichkeitssuchen ermöglichen.
Einbettungsfunktionen für Text können beispielsweise Wörter und Phrasen analysieren und sie auf Vektoren abbilden. Vektoren für Wörter mit ähnlicher Bedeutung werden im Vektorraum nahe beieinander platziert, während Vektoren für Wörter mit unterschiedlicher Bedeutung weiter voneinander entfernt platziert werden. Auf diese Weise können Vektordatenbanken effizient nach Wörtern und Sätzen mit ähnlicher Bedeutung suchen, selbst bei undurchsichtigen oder komplexen Abfragen.

Wie misst man die Verwandtschaft von zwei Wörtern?
Wir wissen bereits, dass ähnliche Wörter im Vektorraum nahe beieinander liegen, während nicht verwandte Wörter weit entfernt sind. Aber wie kann man diese "Nähe" effektiv messen? Eine wirksame Methode ist die Kosinusähnlichkeit. Im Gegensatz zum euklidischen Abstand, der den linearen Abstand zwischen Vektoren misst, konzentriert sich die Kosinus-Ähnlichkeit auf den Winkel zwischen ihnen. Je kleiner der Winkel zwischen zwei Vektoren ist, desto näher liegen sie beieinander und desto größer ist ihre Kosinusähnlichkeit. Die Werte der Cosinus-Ähnlichkeit reichen von -1 bis 1, wobei -1 für eine Ähnlichkeit von Null steht (d. h. für Wörter, die nicht miteinander verwandt sind) und 1 für eine maximale Ähnlichkeit (d. h. für Wörter, die in ihrer Bedeutung ähnlich oder verwandt sind).
Cosinus-Ähnlichkeit
Die Cosinus-Ähnlichkeit ist eine Funktion, die bewertet, wie ähnlich sich zwei Vektoren sind, unabhängig von ihrer Größe. Sie wird vor allem in der Textanalyse, beim maschinellen Lernen und beim Information Retrieval verwendet. Die Berechnung der Kosinusähnlichkeit beinhaltet die Ermittlung des Kosinus des Winkels zwischen zwei Vektoren im n-dimensionalen Raum. Der resultierende Wert liegt zwischen -1 und 1, wobei 1 bedeutet, dass die Vektoren identisch sind, 0 bedeutet, dass sie senkrecht zueinander stehen, und -1 bedeutet, dass sie entgegengesetzt ausgerichtet sind. Die Cosinus-Ähnlichkeit ist besonders nützlich, wenn die Ausrichtung der Vektoren wichtig ist, wie z. B. beim Dokumentenabgleich, beim Information Retrieval und bei Empfehlungssystemen.
Sprachmodelle haben die Fähigkeit, Text zu verstehen und zu erzeugen. Dabei handelt es sich im Wesentlichen um Algorithmen, die Wortfolgen analysieren und auf der Grundlage großer Mengen von Trainingsdaten vorhersagen können, welche Wörter oder Sätze wahrscheinlich folgen werden. Moderne Sprachmodelle wie GPT (Generative Pre-trained Transformer) basieren auf Deep Learning und verwenden komplexe neuronale Netze zur Textverarbeitung.
Sprachmodelle und Einbettungen sind eng miteinander verbunden, da Einbettungen ein Produkt dieser Modelle sind. Wenn ein Sprachmodell Text verarbeitet, wandelt es ihn in eine Einbettung um, die dann in einer Vektordatenbank gespeichert und indiziert werden kann. Dieser Prozess ermöglicht ein hocheffizientes Abrufen und Abgleichen von Textinformationen auf der Grundlage ihrer semantischen Ähnlichkeit, was beispielsweise beim Abrufen relevanter Dokumente, bei der Beantwortung von Anfragen oder bei der Erstellung personalisierter Empfehlungen nützlich ist.
Welche Vektordatenbank und Technologien bevorzugen wir bei TRITON IT für die KI-gestützte Entwicklung?
Bei TRITON IT arbeiten wir täglich mit KI, und im Herbst 2023 haben wir mit der Vorbereitung zweier neuer Investitionsprojekte begonnen, bei denen Vektordatenbanken zum Einsatz kommen. Die Wahl fiel auf ChromaDB, nachdem wir die verfügbaren Implementierungen im Hinblick auf die Projektanforderungen geprüft hatten. Diese Wahl erwies sich aus den folgenden Gründen als ideal:
Vollständige Kompatibilität mit der OpenAI API: ChromaDB ermöglicht eine nahtlose Integration mit der OpenAI API, was die Verwendung fortgeschrittener Sprachmodelle in Anwendungen erleichtert.
Offene Quelle und Transparenz.
Bewährte Technologie: ChromaDB ist eine bewährte und weit verbreitete Datenbank mit einer aktiven (und wachsenden) Gemeinschaft von Benutzern und Entwicklern.
Wir sahen auch die Verfügbarkeit eines Java-Treibers als einen der Vorteile von ChromaDB an. Da wir jedoch für unsere Backend-Microservices-Anwendungen von Java auf Python umgestiegen sind, verwenden wir ChromaDB nativ in Python.
Was ist bei der Entwicklung einer Vektordatenbank zu beachten?
Beim Entwurf einer Vektordatenbank ist es wichtig, über die Wahl der optimalen Einbettungsfunktion nachzudenken. Manchmal kann es sinnvoll sein, die Duplizierung von Daten gegen die Möglichkeit einzutauschen, die Daten mit verschiedenen Einbettungsfunktionen zu kodieren. Der Datenbankarchitekt sollte also nach einer optimalen Lösung suchen, die die Art der zu lösenden Aufgaben, die Geschwindigkeit des Datenzugriffs, die Mindestgröße der gespeicherten Daten und die effiziente Synchronisierung von Änderungen innerhalb doppelter Sammlungen berücksichtigt.
Der Schlüssel liegt darin, zu wissen, ob wir mit einsprachigen Modellen arbeiten wollen und Textdaten nach Sprachen getrennt haben oder ob wir mit mehrsprachigen Modellen arbeiten müssen. Von den frei verfügbaren Modellen hat sich Paraphrase multilingual MPNet Base v2 von Hugging face für uns bei TRITON IT als am nützlichsten erwiesen.