Vector databases in AI – what are vector databases and why are they so effective?
What is a vector database?
Vector databases differ from standard relational databases in their specific approach to storing information. Instead of tables and rows, vector databases store data in the form of vectors. Vectors are mathematical structures that represent data as sets of numbers. This representation method allows vector databases to achieve high efficiency in data storage and retrieval, especially in AI-related tasks.
Vector
A vector is a mathematical object that has size and direction. It is used in various fields, for example, in linear algebra a vector is represented as an ordered tuple of numbers that can describe the position of a point in n-dimensional space. Vectors are the building blocks for many advanced mathematical and scientific concepts.
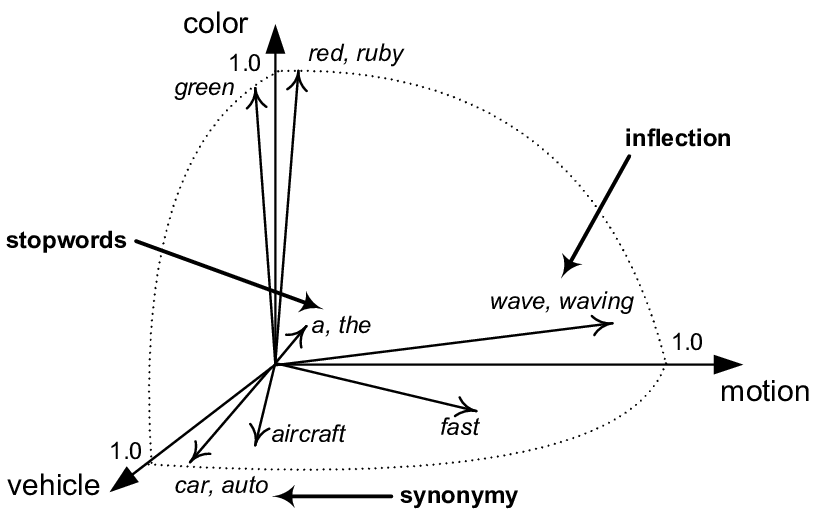
The main strength of vector databases lies in their ability to deal with data in what is called vector space. In this space, similar items are represented by vectors that are in close proximity. This allows vector databases to easily and efficiently retrieve items similar to a given query, even for obscure or complex queries. This feature is crucial for AI applications as it allows machine learning models and natural language processing systems to efficiently learn from data and perform tasks such as classification, clustering, and data analysis.
Clustering
Clustering, or clustering, is a method in machine learning and data analysis that is used to divide a set of data into groups, or "clusters". The goal is to make the data within a cluster as similar as possible, while the data in different clusters is as different as possible. Clustering allows for a better understanding of the structure and properties of the data without the need for prior knowledge of the data partitioning.
Data represented by vectors - what are embedding functions?
To take advantage of vector databases, all data must be converted into vectors. Embeddings functions play a key role in this process. Embeddings functions are mathematical tools that transform data into vector space. These functions analyze the data and extract important information from the data, which they then encode into vector representations. Embeddings functions can be used for a variety of data types, including text, images, and audio.
Embedding functions
Function embedding is a technique used in machine learning and natural language processing that converts objects such as words, images, or user profiles into high-dimensional vector representations. These vector representations preserve semantic relationships between objects, meaning that similar objects will have similar vectors. For example, the vector representation of the word "king" will have a close relationship to the vectors of the words "queen" and "crown". Embeddings make it easier to work with data in neural networks and other machine learning algorithms by enabling efficient comparison, classification, and similarity search.
For example, embeddings functions for text can parse words and phrases and map them to vectors. Vectors for words with similar meanings will be placed close together in the vector space, while vectors for words with different meanings will be placed further apart. This allows vector databases to efficiently search for words and phrases with similar meanings, even for obscure or complex queries.

How do you measure the relatedness of two words?
We already know that similar words are close together in vector space, whereas unrelated words are far away. But how do we effectively measure this "closeness"? An effective method is called cosine similarity. Unlike Euclidean distance, which measures the linear distance between vectors, cosine similarity focuses on the angle between them. The smaller the angle between two vectors, the closer they are and the greater their cosine similarity. The values of cosine similarity range from -1 to 1, where -1 indicates zero similarity (i.e., words that are unrelated) and 1 indicates maximum similarity (i.e., words that are similar in meaning or related in meaning).
Cosine similarity
Cosine similarity is a function that evaluates how similar two vectors are, regardless of their size. It is primarily used in text analysis, machine learning, and information retrieval. Computing cosine similarity involves finding the cosine of the angle between two vectors in n-dimensional space. The resulting value is between -1 and 1, where 1 means the vectors are identical, 0 means they are perpendicular to each other, and -1 means they are oppositely oriented. Cosine similarity is particularly useful when the orientation of vectors is important, such as in document matching, information retrieval, and recommender systems.
Language models have the ability to understand and generate text. Basically, these are algorithms that analyze sequences of words and are able to predict what words or phrases are likely to follow based on large amounts of training data. Modern language models such as GPT (Generative Pre-trained Transformer) are based on deep learning and use complex neural networks to process text.
Language models and embeddings are closely linked, as embeddings are a product of these models. When a language model processes text, it converts it into an embedding, which can then be stored and indexed in a vector database. This process enables highly efficient retrieval and matching of textual information based on its semantic similarity, which is useful, for example, in retrieving relevant documents, answering queries, or making personalized recommendations.
What vector database and technologies do we prefer at TRITON IT for AI-enabled development?
At TRITON IT , we work with AI on a daily basis, and during the autumn of 2023 we started preparing two new investment projects using vector databases. ChromaDB was selected after reviewing the available implementations with respect to the project requirements. This choice proved to be ideal for the following reasons:
Full compatibility with OpenAI API: ChromaDB allows seamless integration with the OpenAI API, making it easy to use advanced language models in applications.
Open source and transparency.
Proven technology: ChromaDB is a proven and widely used database with an active (and growing) community of users and developers.
We also saw the availability of a Java driver as one of the advantages of ChromaDB. However, due to our transition from Java to Python for backend microservices applications, we use ChromaDB natively in Python.
What to keep in mind when designing a vector database?
When designing a vector database, it is important to think about choosing the optimal embedding function. It can sometimes be useful to trade the duplication of a piece of data for the ability to have the data encoded using different embedding functions. Thus, the database architect should look for the optimal solution with respect to the type of tasks to be solved, the speed of data access, the minimum size of the stored data, and the efficient synchronization of changes within duplicate collections.
The key is to know whether we want to work with monolingual models and have text data separated by language or whether we need to work with multi-language models. Of the freely available ones, Paraphrase multilingual MPNet Base v2 from Hugging face has been the most useful for us at TRITON IT.
Do you want to develop your business with us using AI?
Related articles
COLORIT is one of the long-established players on the Czech B2B and B2C market for paints, varnishes and sealants. Its position has not been...
Libeřské lahůdky offers its delicacies in 21 shops not only in Prague, but also in České Budějovice, for example, and new branches are regularly...
Saleor is an open platform written in Python that provides a complete backend for creating an e-shop and implements all essential processes,...