Vectordatabases in AI – wat zijn vectordatabases en waarom zijn ze zo effectief?
Wat is een vector database?
Vectordatabases verschillen van standaard relationele databases door hun specifieke benadering van het opslaan van informatie. In plaats van tabellen en rijen slaan vectordatabases gegevens op in de vorm van vectoren. Vectoren zijn wiskundige structuren die gegevens voorstellen als verzamelingen getallen. Dankzij deze representatiemethode kunnen vectordatabases een hoge efficiëntie bereiken bij het opslaan en ophalen van gegevens, vooral bij AI-gerelateerde taken.
Vector
Een vector is een wiskundig object met grootte en richting. Het wordt gebruikt in verschillende domeinen, bijvoorbeeld in lineaire algebra wordt een vector voorgesteld als een geordend aantal getallen die de positie van een punt in een n-dimensionale ruimte kunnen beschrijven. Vectoren zijn de bouwstenen voor veel geavanceerde wiskundige en wetenschappelijke concepten.
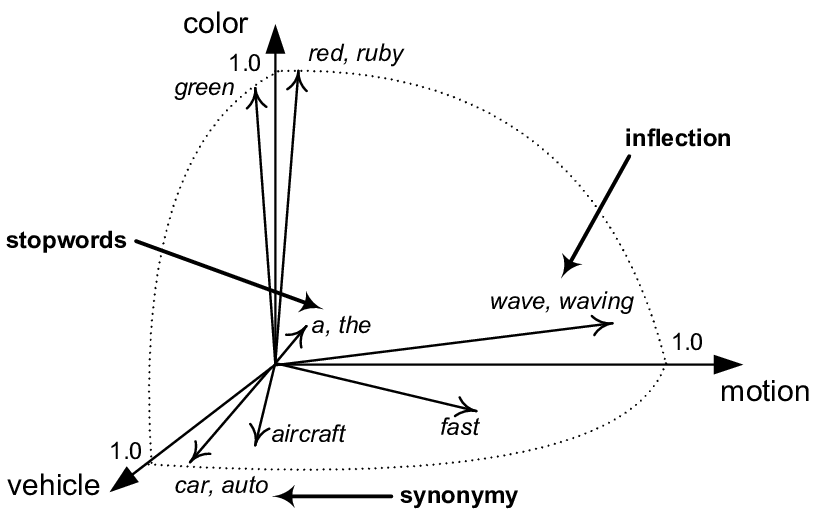
De belangrijkste kracht van vectordatabases ligt in hun vermogen om om te gaan met gegevens in de zogenaamde vectorruimte. In deze ruimte worden gelijkaardige items voorgesteld door vectoren die dicht bij elkaar liggen. Hierdoor kunnen vectordatabases gemakkelijk en efficiënt items vinden die lijken op een gegeven zoekopdracht, zelfs voor onduidelijke of complexe zoekopdrachten. Deze eigenschap is cruciaal voor AI-toepassingen omdat het machine-leermodellen en natuurlijke taalverwerkingssystemen in staat stelt om efficiënt te leren van gegevens en taken uit te voeren zoals classificatie, clustering en gegevensanalyse.
Clusteren
Clusteren, of clusteren, is een methode in machinaal leren en gegevensanalyse die wordt gebruikt om een verzameling gegevens in groepen, of "clusters", te verdelen. Het doel is om de gegevens binnen een cluster zo gelijk mogelijk te maken, terwijl de gegevens in verschillende clusters zo verschillend mogelijk zijn. Clusteren maakt het mogelijk om de structuur en eigenschappen van de gegevens beter te begrijpen zonder dat er voorkennis nodig is over de verdeling van de gegevens.
Gegevens voorgesteld door vectoren - wat zijn inbeddingsfuncties?
Om voordeel te halen uit vectordatabases, moeten alle gegevens worden omgezet in vectoren. Embeddingsfuncties spelen een sleutelrol in dit proces. Embeddingsfuncties zijn wiskundige hulpmiddelen die gegevens transformeren naar vectorruimte. Deze functies analyseren de gegevens en halen belangrijke informatie uit de gegevens, die ze vervolgens coderen in vectorvoorstellingen. Embeddingsfuncties kunnen worden gebruikt voor een verscheidenheid aan gegevenstypen, waaronder tekst, afbeeldingen en audio.
Functies insluiten
Functie-inbedding is een techniek die wordt gebruikt in machinaal leren en natuurlijke taalverwerking die objecten zoals woorden, afbeeldingen of gebruikersprofielen omzet in hoog-dimensionale vectorrepresentaties. Deze vectorvoorstellingen behouden semantische relaties tussen objecten, wat betekent dat gelijkaardige objecten gelijkaardige vectoren zullen hebben. Bijvoorbeeld, de vectorrepresentatie van het woord "koning" zal een nauwe relatie hebben met de vectoren van de woorden "koningin" en "kroon". Embeddings maken het gemakkelijker om met gegevens te werken in neurale netwerken en andere algoritmen voor machinaal leren door efficiënte vergelijking, classificatie en zoeken naar gelijkenissen mogelijk te maken.
Embeddings functies voor tekst kunnen bijvoorbeeld woorden en zinnen ontleden en ze in vectoren omzetten. Vectoren voor woorden met gelijkaardige betekenissen zullen dicht bij elkaar geplaatst worden in de vectorruimte, terwijl vectoren voor woorden met verschillende betekenissen verder uit elkaar geplaatst zullen worden. Hierdoor kunnen vectordatabases efficiënt zoeken naar woorden en zinnen met vergelijkbare betekenissen, zelfs voor onduidelijke of complexe zoekopdrachten.

Hoe meet je de verwantschap van twee woorden?
We weten al dat gelijksoortige woorden dicht bij elkaar staan in de vectorruimte, terwijl niet-verwante woorden ver weg staan. Maar hoe kunnen we deze "nabijheid" effectief meten? Een effectieve methode heet cosinusovereenkomst. In tegenstelling tot Euclidische afstand, die de lineaire afstand tussen vectoren meet, richt cosinus gelijkenis zich op de hoek tussen de vectoren. Hoe kleiner de hoek tussen twee vectoren, hoe dichter ze bij elkaar liggen en hoe groter hun cosinusovereenkomst. De waarden van cosinusovereenkomst gaan van -1 tot 1, waarbij -1 gelijkenis nul aangeeft (woorden die niet verwant zijn) en 1 maximale gelijkenis (woorden die gelijkaardig zijn in betekenis of verwant in betekenis).
Cosinusovereenkomst
Cosinusovereenkomst is een functie die evalueert hoe gelijkaardig twee vectoren zijn, ongeacht hun grootte. Het wordt voornamelijk gebruikt in tekstanalyse, machinaal leren en het ophalen van informatie. Het berekenen van cosinus gelijkenis bestaat uit het vinden van de cosinus van de hoek tussen twee vectoren in een n-dimensionale ruimte. De resulterende waarde ligt tussen -1 en 1, waarbij 1 betekent dat de vectoren identiek zijn, 0 betekent dat ze loodrecht op elkaar staan en -1 betekent dat ze tegengesteld georiënteerd zijn. Cosinusovereenkomst is vooral nuttig wanneer de oriëntatie van vectoren belangrijk is, zoals bij het matchen van documenten, het ophalen van informatie en aanbevelingssystemen.
Taalmodellen kunnen tekst begrijpen en genereren. Dit zijn algoritmen die woordreeksen analyseren en kunnen voorspellen welke woorden of zinnen waarschijnlijk zullen volgen op basis van grote hoeveelheden trainingsgegevens. Moderne taalmodellen zoals GPT (Generative Pre-trained Transformer) zijn gebaseerd op deep learning en gebruiken complexe neurale netwerken om tekst te verwerken.
Taalmodellen en embeddings zijn nauw met elkaar verbonden, aangezien embeddings een product zijn van deze modellen. Wanneer een taalmodel tekst verwerkt, zet het deze om in een embedding, die vervolgens kan worden opgeslagen en geïndexeerd in een vector database. Dit proces maakt zeer efficiënt ophalen en matchen van tekstuele informatie mogelijk op basis van de semantische gelijkenis, wat bijvoorbeeld nuttig is bij het ophalen van relevante documenten, het beantwoorden van zoekopdrachten of het doen van gepersonaliseerde aanbevelingen.
Welke vector database en technologieën hebben onze voorkeur bij TRITON IT voor AI-gebaseerde ontwikkeling?
Bij TRITON IT werken we dagelijks met AI en in de herfst van 2023 zijn we begonnen met de voorbereiding van twee nieuwe investeringsprojecten waarbij we gebruikmaken van vectordatabases. ChromaDB werd geselecteerd na een evaluatie van de beschikbare implementaties met betrekking tot de projectvereisten. Deze keuze bleek ideaal om de volgende redenen:
Volledige compatibiliteit met OpenAI API: ChromaDB maakt naadloze integratie met de OpenAI API mogelijk, waardoor het eenvoudig is om geavanceerde taalmodellen in applicaties te gebruiken.
Open bron en transparantie.
Bewezen technologie: ChromaDB is een bewezen en veelgebruikte database met een actieve (en groeiende) gemeenschap van gebruikers en ontwikkelaars.
We zagen de beschikbaarheid van een Java-driver ook als een van de voordelen van ChromaDB. Echter, door onze overgang van Java naar Python voor backend microservices toepassingen, gebruiken we ChromaDB native in Python.
Waar moet je op letten bij het ontwerpen van een vector database?
Bij het ontwerpen van een vector database is het belangrijk om na te denken over het kiezen van de optimale inbeddingsfunctie. Het kan soms nuttig zijn om de duplicatie van een stuk data te ruilen voor de mogelijkheid om de data te coderen met verschillende inbeddingsfuncties. De database architect moet dus zoeken naar de optimale oplossing met betrekking tot het type taken dat opgelost moet worden, de snelheid van gegevenstoegang, de minimale grootte van de opgeslagen gegevens en de efficiënte synchronisatie van wijzigingen binnen dubbele verzamelingen.
De sleutel is om te weten of we willen werken met eentalige modellen en tekstgegevens gescheiden willen hebben per taal of dat we moeten werken met meertalige modellen. Van de vrij beschikbare modellen is Paraphrase meertalige MPNet Base v2 van Hugging face voor ons bij TRITON IT het nuttigst gebleken.
Wilt u samen met ons uw bedrijf ontwikkelen met behulp van AI?
Verwante artikelen
Op dinsdag 21 april veranderde het Praagse beursterrein in Holešovice in een centrum van technologische innovatie. Hier vond namelijk de eerste...
COLORIT is een van de langdurig gevestigde spelers op de Tsjechische B2B- en B2C-markt voor verf, lak en kit. Haar positie is niet tot stand...
Libeřské lahůdky biedt zijn delicatessen al aan in 21 winkels, niet alleen in Praag, maar ook in bijvoorbeeld České Budějovice, en er komen...