Vektorové databáze v AI – co to jsou vektorové databáze a proč jsou tak efektivní?
Co to je vektorová databáze?
Vektorové databáze se odlišují od standardních relačních databází specifickým přístupem k ukládání informací. Místo tabulek a řádků vektorové databáze ukládají data ve formě vektorů. Vektory jsou matematické struktury, které reprezentují data jako soubory čísel. Tento způsob reprezentace umožňuje vektorovým databázím dosahovat vysoké efektivity při ukládání a vyhledávání dat, a to především v úlohách souvisejících s AI.
Vektor
Vektor je matematický objekt, který má velikost a směr. Využívá se v různých oblastech, například v lineární algebře se vektor reprezentuje jako uspořádaná n-tice čísel, která mohou popisovat pozici bodu v n-rozměrném prostoru. Vektory jsou základním stavebním kamenem pro mnoho pokročilých matematických a vědeckých konceptů.
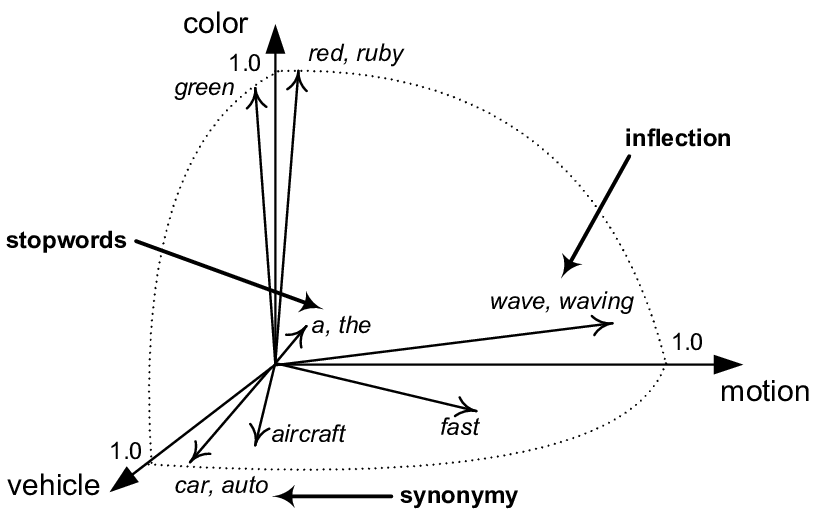
Hlavní síla vektorových databází je v jejich schopnosti pracovat s daty v tzv. vektorovém prostoru. V tomto prostoru jsou podobné položky reprezentovány vektory, které se nacházejí v těsné blízkosti. To umožňuje vektorovým databázím snadno a efektivně vyhledávat položky podobné danému dotazu, a to i v případě nejasných nebo komplexních dotazů. Tato vlastnost je pro AI aplikace klíčová, jelikož umožňuje modelům strojového učení a systémům pro zpracování přirozeného jazyka efektivně se učit z dat a provádět úkoly jako je klasifikace, clustering a analýza dat.
Clustering
Clustering, neboli shlukování, je metoda v oblasti strojového učení a analýzy dat, která slouží k rozdělení souboru dat na skupiny, neboli "shluky". Cílem je, aby data v rámci jednoho shluku byla co nejvíce podobná, zatímco data v různých shlucích byla co nejvíce odlišná. Clustering umožňuje lépe porozumět struktuře a vlastnostem dat bez nutnosti předchozích znalostí o jejich rozdělení.
Data reprezentována vektory - co to jsou embedding funkce?
Abychom mohli využívat výhod vektorových databází, musí být veškerá data převedena na vektory. Klíčovou roli v tomto procesu hrají embeddings funkce. Embeddings funkce jsou matematické nástroje, které transformují data do vektorového prostoru. Tyto funkce analyzují data a extrahují z nich důležité informace, které pak zakódují do vektorových reprezentací. Embeddings funkce se dají použít pro různé typy dat, včetně textu, obrázků a zvuku.
Embedding funkce
Embedding funkce je technika používaná v oblasti strojového učení a zpracování přirozeného jazyka, která převádí objekty, jako jsou slova, obrázky nebo uživatelské profily, do vysoce-dimenzionálních vektorových reprezentací. Tyto vektorové reprezentace zachovávají sémantické vztahy mezi objekty, což znamená, že podobné objekty budou mít podobné vektory. Například vektorová reprezentace slova "král" bude mít blízký vztah k vektorům slov "královna" a "koruna". Embeddingy usnadňují práci s daty v neuronových sítích a dalších algoritmech strojového učení tím, že umožňují efektivní srovnávání, klasifikaci a hledání podobností.
Například embeddings funkce pro text mohou analyzovat slova a fráze a mapovat je do vektorů. Vektory pro slova s podobným významem budou v vektorovém prostoru umístěny blízko u sebe, zatímco vektory pro slova s odlišným významem budou umístěny dále od sebe. To umožňuje vektorovým databázím efektivně vyhledávat slova a fráze s podobným významem, a to i v případě nejasných nebo komplexních dotazů.

Jak se měří příbuznost dvou slov?
Už víme, že podobná slova jsou ve vektorovém prostoru blízko sebe, kdežto ta slova, která spolu nesouvisí, se nachází daleko. Jakým způsobem ale efektivně měřit tuto “blízkost”? Účinnou metodou je tzv. kosinova podobnost. Na rozdíl od Euklidovské vzdálenosti, která měří přímkovou vzdálenost mezi vektory, kosinová podobnost se zaměřuje na úhel mezi nimi. Čím menší je úhel mezi dvěma vektory, tím si jsou bližší a tím větší je jejich kosinová podobnost. Hodnoty kosinové podobnosti se pohybují v rozmezí od -1 do 1, kde -1 indikuje nulovou podobnost (tzn. slova, která spolu nesouvisí) a 1 indikuje maximální podobnost (tzn. slova, která mají podobný význam nebo spolu významově souvisejí).
Kosinová podobnost
Kosinová podobnost je funkce, která hodnotí, jak podobné jsou dva vektory, nezávisle na jejich velikosti. Využívá se především v textové analýze, strojovém učení a informačním vyhledávání. Výpočet kosinové podobnosti spočívá ve zjištění kosinu úhlu mezi dvěma vektory v n-rozměrném prostoru. Výsledná hodnota je mezi -1 a 1, kde 1 znamená, že vektory jsou identické, 0 znamená, že jsou na sebe kolmé, a -1, že jsou opačně orientované. Kosinová podobnost je užitečná zejména v případech, kdy je důležitá orientace vektorů, například při porovnávání dokumentů, vyhledávání informací a doporučovacích systémech.
Jazykové modely mají schopnost porozumět a generovat text. V zásadě se jedná o algoritmy, které analyzují sekvence slov a na základě velkého množství tréninkových dat jsou schopny předpovídat, jaká slova či fráze budou pravděpodobně následovat. Moderní jazykové modely, jako je například GPT (Generative Pre-trained Transformer), jsou založeny na hlubokém učení a využívají složité neuronové sítě ke zpracování textu.
Jazykové modely a embeddingy jsou úzce propojeny, protože embeddingy jsou produktem těchto modelů. Když jazykový model zpracuje text, převádí ho do embeddingu, který pak může být uložen a indexován ve vektorové databázi. Tento proces umožňuje vysoce efektivní vyhledávání a porovnávání textových informací na základě jejich sémantické podobnosti, což je užitečné například při vyhledávání relevantních dokumentů, odpovědí na dotazy nebo personalizovaných doporučeních.
Jakou vektorovou databázi a technologie preferujeme v TRITON IT pro vývoj s AI?
V TRITON IT s umělou inteligencí pracujeme na denní bázi a během podzimu roku 2023 jsme začali připravovat dva nové investiční projekty, ve kterých využíváme vektorové databáze. Po prozkoumání dostupných implementací s ohledem na požadavky projektů byla vybrána ChromaDB. Tato volba se ukázala jako ideální z následujících důvodů:
Plná kompatibilita s OpenAI API: ChromaDB umožňuje bezproblémovou integraci s OpenAI API, čímž usnadňuje využití pokročilých jazykových modelů v aplikacích.
Otevřený kód a transparentnost: ChromaDB je open-source projekt s otevřeným kódem a srozumitelnou dokumentací, čímž zajišťuje transparentnost a umožňuje komunitní vývoj.
Ověřená technologie: ChromaDB je prověřená a rozšířená databáze s aktivní (a rostoucí) komunitou uživatelů a vývojářů.
Jako jednu z výhod ChromaDB jsme spatřovali rovněž dostupný Java driver. Nicméně vzhledem k našemu přechodu z Javy na Python pro backendové microservices aplikace, využíváme ChromaDB nativně v jazyce Python.
Na co myslet při návrhu vektorové databáze?
Při návrhu vektorové databáze je důležité myslet na volbu optimální embedding funkce. Leckdy může být vhodné vyměnit duplicitu části dat za možnost mít data zakódována pomocí různých embedding funkcí. Databázový architekt by tak měl hledat optimální řešení vzhledem k typu řešených úloh, rychlosti přístupu k datům, minimální velikosti uložených dat i efektivní synchronizaci změn v rámci duplicitních kolekcí.
Klíčové je vědět, zda chceme pracovat s mono-jazykovými modely a mít textová data separována podle jazykových mutací, nebo zda potřebujeme pracovat s multi-jazykovými modely. Z těch volně dostupných se nám v TRITON IT nejvíce osvědčil Paraphrase multilingual MPNet Base v2 od Hugging face.
Chcete s námi rozvíjet váš byznys za pomoci AI?
Související články
Společnost COLORIT patří mezi dlouhodobě etablované hráče na českém B2B i B2C trhu s barvami, laky a tmely. Její pozice nevznikala agresivním...
Libeřské lahůdky nabízí své delikatesy již na 21 prodejnách nejen v Praze, ale třeba také v Českých Budějovicích, a pravidelně další pobočky...
Saleor je otevřená platforma napsaná v Pythonu, která poskytuje kompletní backend pro tvorbu e-shopu a implementuje všechny zásadní procesy,...